从PC时代到移动互联网时代,搜索知足了人们从海量信息中找到有价值信息的需求,进一步提高了用户的信息消费能力和获取信息效率。笔者曾做过一个对照简朴的APP站内搜索功效优化,查阅了许多搜索功效设计资料。
于是乎便有了这篇搜索文章,我将从搜索最主要的三步明白用户搜索意图、召回内容、排序内容来给人人讲讲搜索功效设计的那些事。


纲领如下:
- 搜索是为领会决什么
- 若何设计站内搜索
- 明白用户搜索意图
- 召回内容
- 排序内容
- query剖析
- 写在最后
一、搜索是为领会决什么
搜索引擎在PC时代崛起,谷歌、百度通过输入框和网页搜索效果来知足网民的信息消费,辅助网民打破种种信息不对称。谷歌、百度的搜索信息是相对开放的,用户能在上面搜到大部门的内容。
随着移动互联网的普及,许多APP最先构建自己的内容生态,搭建自身的站内搜索。谷歌、百度等搜索引擎时从搜索到内容,这些站内搜索是从内容到搜索,基于自家的内容生态来搭建搜索功效。
对于用户来说,用户搜索内容可分为几种场景:
- 有明确想搜的内容并记得所有关键词
- 有明确想搜的内容但记不清所有关键词
- 无明确想搜的内容
以是对于用户来说,搜索是为领会决用户明确或者不明确的搜索需求,让用户能够搜到想搜的内容。从更深一层来说,搜索提高了用户获取信息、内容的效率。
二、若何设计站内搜索
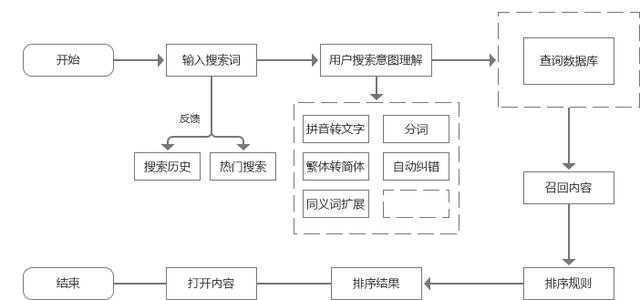
站内搜索对于搜索系统来说,整个流程可以分为三步,划分是:
- 明白用户搜索意图
- 召回内容
- 排序内容
整个流程里,第一步明白用户搜索意图会涉及到query预处置、分词手艺等手艺,第二步召回相关内容一样平常用到的是索引倒序的手艺,召回有相关性的内容,这里会涉及到倒排索引和匹配度问题。第三步排序内容现在常见的有排序计谋、机械学习。
产物司理需要做的主要是画搜索原型图和制订召回相关性计谋和排序计谋,其他的主要是靠手艺或者第三方去实现。
三、明白用户搜索意图
用户搜索是整个搜索系统的上游,只有明白了用户的搜索意图,搜索展现的效果才会是用户想要的。若是对搜索意图明白错了,岂论我们的召回率和排序计谋何等牛,对用户来说这次的搜索实在是失败的。
那么怎么明白用户的搜索意图呢?用户输入的是关键词,以是我们来剖析下怎么明白关键词。(ps:这篇文章只讨论搜索方式为输入文字的方式,不讨论语音输入、图片、视频输入等方式)
3.1 query预处置
3.1.1 拼音转文字
当用户在搜索框中输入拼音时,可以识别出文字。这种搜索场景照样蛮常见的,好比用户想在微信念书中搜索“俞军产物方式论”,那么当用户在搜索框中输入”yujunchnapinfangfalun”时能明白出“俞军产物方式论”,并给出搜索效果。
3.1.2 繁体转简体
对于一些有繁体输入习惯的用户,需要对用户输入的繁体字举行转化,可以识别出其简体。详细方案是通过词表将繁体query转化为简体query,后续系统在将简体query举行召回。
3.1.3 自动纠错
当用户在搜索框中输入“于军”,实在用户想搜的是“俞军”。系统可以对这个query举行判断,判断有没有在索引库掷中文档,若是没有,则需要对其举行预处置的自动纠错。
自动纠错可以通过维护纠错表的方式实现。在纠错内外通过映射原词给纠错后的词,从而实现query改写。
现在自动纠错在客户端显示上也有几种差其余形式:
- 强纠错:直接改写query,给用户的提醒一样平常为“已显示XXX的搜索效果”
- 中纠错:直接改写query,给用户的提醒一样平常为“已显示XXX的搜索效果,仍然搜索:X原词XX”
- 弱纠错:不改写query,只是给用户提醒“你是不是要搜索:XXX”
3.1.4 同义词转换
同义词转换从字面上明白就是能够对query举行同义词的明白。好比当用户输入“首都机场”,可以明白为“北京机场”,用户输入“国宝”,可以明白为“大熊猫”。
同义词转换手艺对于query意图明白异常主要,许多时刻用户不能很好地输出自己想搜索的内容,若是没有同义词转换手艺进一步处置,那么召回的内容很有可能并不是用户想要的。
同义词转换手艺一样平常是通过获取用户的session日志来剖析相关的query。
举个例子,好比一个用户输入”国宝“后,查询出来的效果不是想要的,从而没有点击行为。该用户接着输入“大熊猫”,得到了想要的搜索效果并点击了内容。那么“国宝”和”大熊猫“之间就确立了联系。
固然,”国宝“也有可能和”国家宝藏”、“国家文物”等确立联系,基于统计后,可以盘算出“国宝”与其余词的联系权重。在召回相关性内容时,对关键词和同义词举行召回,并赋予差其余权重,权重分值可以放在相关性分数上。
3.2 分词手艺
以微信念书为例子,现在微信念书的搜索效果内容为书、民众号文章、民众号。好比用户在微信念书上输入“无限的游戏”,用户的意图是想查找一本名为“有限与无限的游戏”的书,不外记错为“无限的游戏”。
若是词典里没有“无限的游戏”这个词,那么就无法返回对应的内容,用户的搜索就到此结束。
词典的词是有限的,输入的关键词是无限的。为领会决这种情形,现在搜索系统主要是通过分词手艺来实现。分词的意思是将关键词切分成多个词。
好比“无限的游戏“可以切分为“无限”“的”“游戏”,接纳差其余分词手艺出来的分词效果也差别。好比有了“无限”“的”“游戏”后,分词会对应到词典里的词,有对应的索引内容,召回了“有限与无限的游戏”这本书。
中文分词现在有三种分词方式,划分是:
- 基于词典的分词
- 基于语法的分词
- 基于统计的分词
第一种基于词典的分词方式用的对照多,我简朴地为人人先容一下。
基于词典的分词指的就是系统有一个词典库,当query的分词与词典的词对应上了,就能召回词典对应的索引文档。
分词的粒度也是至关主要的,现在有许多这方面的规则和算法。对照经典的有正向最大匹配、逆向最大匹配的规则、MMSEG算法。
经由分词切割后,用户非尺度的query就能被切分成尺度的分词,并能在词典中匹配到词,从而能索引回相关的内容。
固然产物司理不需要醒目这些手艺,领会观点和实现的效果即可。产物司理提出来的需求有可能是手艺部门不支持的,或者不是该功效的最优方案。以是领会这些最基本的手艺原理,有助于我们更好地设计搜索功效和提合理的搜索需求。
四、召回内容
4.1 倒排索引手艺
这一节,我们需要先说下搜索很焦点的手艺——倒排索引手艺。
搜索系统有词典和内容索引库(数据库),词典里的词关联匹配内容索引库。当用户输入关键词后,若是词典里有这个词,线上会快速召回内容文档。若是词典里没有这个词,那这次的搜索行为就没有效果。
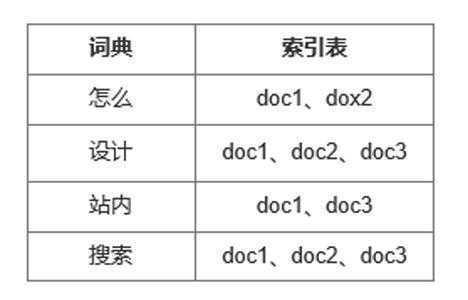
假设内容索引库一共只有3个内容文档,划分是:
- doc1:站内搜索从0到1全流程设计
- doc2:搜索应该怎么设计才是对的
- doc3:产物小白怎么入门站内搜索设计
用户输入关键词“怎么设计站内的搜索”,经由分词后,词典里有这个词,系统会召回对应的索引文档。
索引库如下图所示:
以新闻搜索来说,一条新闻讯息一样平常会有题目、简介、关键词、泉源、正文。
在召回内容的时刻,会凭据新闻的这几个属性划分构建倒排索引。固然需要召回的字段属性是需要思量的,并非所有属性都得举行索引召回。
好比可以只对题目和简介这两个属性举行倒排索引召回。召回的时刻,我们以为题目跟关键词匹配度高于简介跟关键词的匹配度,可以先以题目为维度倒排索引举行召回,接着再从简介举行召回。
这样的分级索引库有利于提高检索效率,同时能较快将优质和匹配度高的内容检索出来。
五、排序内容
召回相关的内容后,若何排序呢?排序的计谋决议了用户最终看到怎样的搜索效果,以是这部门是相当主要的,同时也是对照庞大的。
我这里提供两种排序计谋,一种粗排,一种精排(精排、粗排的叫法只是我为了区分两种排序计谋而界说的)。产物司理要凭据详细的搜索营业和需求来制订搜索排序计谋。
5.1 粗排计谋
粗排主要是通过维度来将召回的内容举行排序。以某新闻app为例,搜索效果只是新闻(新闻内容包罗图文、纯文本、视频)。召回的局限是新闻题目和摘要。
召回的内容匹配度分两个品级:
- 完全匹配
- 模糊匹配(前缀、后缀、分词等)
排序计谋:
运营角度看“一带一盔”热
优先度:新闻题目>摘要,在优先度下根据下方的计谋:
I.完全匹配>模糊匹配
II.时效性(以天为单元)
III.阅读量优先
以上的粗排计谋只是为了解说,详细的维度和排序指标纷歧定是我上面提及的。
5.2 精排计谋
精排计谋是凭据doc分数倒序排序。用户输入query后,召回了doc(内容),这些doc怎么排序泛起给用户呢?谜底是凭据每个doc的分数倒序泛起给用户。
doc分数=文本相关性的值*主要度的值。
文本相关性的值用dscore示意、主要度的值用Iscore来示意,则doc分数=dscore*Iscore。
5.2.1 文本相关性
文本相关性的数值怎么盘算呢?现在业界盘算相关性的方式主要有三种,划分是tf-idf文本相关性、基于统计词频的BM25、空间向量模子。
我在这里给人人先容下异常经典的tf-idf文本相关性方式。这个方式不仅简朴,并且能解决80%以上的搜索效果相关性问题。
5.2.1.1 Tf-idf
Tf-idf中的tf全称为Term Frequence,指的是词频,是指该词在某文本的占比。Tf越高,说明该词在文本中越主要。
Idf全称为Inverse Document Frequence,指的是逆文档频率。在说idf前先先容下df,df是文档频率,是将包罗该Term的文档数除以总文档数。好比一个Term在10个文档泛起,总共有50个文档,那么df值为10/50(1/5)。
讲完df后,我们再聊回idf,照样上面的例子,那么idf值为log(50/10)。由公式可以看出,idf越高,说明有该Term的文本越少,那么该文本越就能代表该Term。
同时用log来示意,还能处置掉一些高频词对文本相关性的滋扰。好比“的”“了”,这种高频词的Tf可能很高,但Idf会很小,接近于0,两数值相乘后也会很小,能很好的清扫这些高频词的噪音。
对于较为简朴的文本相关性排序,相关性的分值可以用Tf*idf来示意,分值越高,说明文本相关性越高。
5.2.1.2 词距与词序
query被切割分词成多个term后,term之间的距离与顺序跟文本相关性有关。
举个例子,用户搜索“产物方式论”,在索引库里正好有两个文档为“俞军产物方式论”和“做产物的10个方式”,很明显召回排序时,“俞军产物方式论”应该要比“做产物的10个方式”排在更前。
但可能这两个文档的Tf*idf值是一样的,由于“产物”和“方式”这两个term都有。以是我们需要关注term之间的距离和顺序,在盘算相关性分值时思量进来,从而保证紧密度更高的term在召回的文档中泛起距离更近更相关。
5.2.1.3 term位置
差别位置相关性的主要水平会差别,以新闻搜索来说,题目与关键词的相关性是要主要于简介与关键词的相关性的。一样平常这种情形下,可以赋予一个系数到Tf*idf,最终dscore=a*Tf*idf(a是系数,好比题目可以赋予1,简介赋予0.8)
5.2 主要度
主要度指得是doc(内容)的主要水平(优质水平)。相关性得分差不多的内容里会存在优质内容和劣质内容,一样平常情形下,我们会将优质内容排在更前面。固然也会有商业、广告或者其余营业的思量,这种情形下主要度得分就会加倍庞大一些。
主要度得分(Tscore)由于跟query没有直接关系,是每一个doc的实时属性,以是这一部门的分数可以离线算好。
照样以新闻搜索为例,假设一条新闻最主要的三个指标是阅读量、谈论率、时效性。那么:Tscore=a*f(阅读量)+b*f(谈论量)+c*f(时效性)。
f(阅读量)、f(谈论量)、f(谈论量)这三个都是函数。一样平常来说,这三个函数可以为对数函数(log函数),由于对数函数是递增函数,但其导数为递减函数,说明随着阅读量增大,f(阅读量)值也会增大,但增大趋势在下降,即增大水平越来越小。
这样有助于冷却一些优质数据,想要获得更高分数会越来越难题,使得马太效应的强度降低一些。
三个对数函数还会存在一个问题,即没有归一化。好比阅读量的值会在0-100000,谈论率在0-1之间,时效性以小时来算的话,时效性的值可以在0-8760(以上数值不具备参考意义,单纯是为了解说)。
三个指标的值不在统一区间,会严重影响最终的主要度得分(Tscore)的真实性。以是需要将三个指标的值归一化,消除量纲,将数据值按比例缩放。
归一化有几种常见的方式,有取分数、min-max尺度化、Z-score尺度化方式等,通过这些方式将三个指标的取值局限控制在0~1。(详细归一化操作人人可自行搜索,不在此睁开)
若何确定a、b、c三个值呢?
一样平常有两种设施:
- 专家、产物自行决议(拍脑壳或者通过多组数据来得出)
- 通过机械学习来训练,得出a、b、c的值
验证这些值是不是对的,可以通过A/Btest、搜索功效上线后的数据来验证。
六、query剖析
搜索功效搭建好之后,若是搜索功效对于整体营业来说很主要,那么我们需要不断地优化搜索功效。优化搜索功效不但单只是优化搜索计谋和算法,还可以通过query剖析来提升用户搜索体验。
query剖析指的是对用户的查询举行剖析,用户的搜索轨迹能够很好的辅助我们领会整体用户的搜索意图,也能发现我们现在的搜索知足了用户哪些搜索需求,哪些搜索需求还需要完善。
query剖析可以分以下几步来操作:
1、以月份为单元,从query中抽取1000个query样本
2、针对query意图举行分类,每个query样本用两个需求分类来表征该query的搜索需求
3、统计一类需求、二类需求query个数的占比情形和搜索次数占比情形
query个数占比=分类query个数/query总数
query搜索次数占比=分类query搜索次数/总query搜索次数
4、统计几个数据:
query召回率=搜索效果在准确的数目/应该被搜索的效果数目
query准确率=搜索效果在准确的数目/返回的效果数目
query需求知足水平,可以凭据搜索效果质量得出query需求知足水平,分为高中低三品级
通过以上四步,我们能获得响应的数据统计,接下来就是需要对数据效果举行剖析,通过剖析来决议下一步搜索需要怎么优化。
举个例子,好比在query需求知足度中,剖析出需求知足度低的query需求是哪些,查看搜索效果,剖析是什么缘故原由导致。
可能会是数据缺失、搜索效果相关度低等缘故原由引起,那么我们后面若是需要提高这类query需求的用户搜索体验的话,那么就需要去解决数据缺失、搜索效果相关度低的问题。
- 若是是数据缺失,那么可以通过引入外面的内容、加大该类内容供应
- 若是是搜索效果相关度低,那么可以改善匹配计谋,召回更相关的内容
七、写在最后
写到最后才发现写了这么多,实在一个完整的站内搜索不仅仅只是这些,明白用户搜索意图、召回内容、排序内容这三步可以优化的地方实在是太多了。
随着搜索需求越来越高,传统的方式无法知足一些搜索场景和目的。以是我们早已最先从算法工程和机械学习切入,这部门我暂时还未涉及,不外最近有在看算法,看看后面能不能从算法的角度来跟人人讲讲若何提高对用户搜索意图剖析、若何提高搜索相关性等。
谈到搜索,在中文搜索里绕不开俞军先生。最后贴一下俞军先生昔时求职搜索事情的求职信,体会下这封至今读来依旧带有传奇色彩的求职信。
搜索引擎9238,男,26岁,上海籍,同济大学化学系五年制,览群书,多游历。97年7月起在一个国营单元筹备入口生产项目。99年4月起在一个署理公司销售入口化工原料兼报关跟单。2000年1月起在一个垂直网络公司做剖析仪器资料采编。2000年7月起去一个网络公司应聘搜索引擎产物司理,却被派去做数据库谋划,9月起任数据中心司理。历久想踏入搜索引擎业,无奈欲投无门,心下甚急,故有此文。若有公司想做最好的中文搜索,诚意乞一介入机遇。
本人热爱搜索成痴,只要是做搜索,不计较地域(无论天南海北,刀山火海),不计较职位(无论崎岖贵贱一线二线,与搜索相关即可),不计较薪水(可维持小我私家当地衣食住行即是底线),不计较事情强度(横竖已习惯了逐日14小时事情制)。
本文来源于自互联网,不代表n5网立场,侵删。发布者:N5网,转载请注明出处:https://www.n5w.com/19048.html
 微信扫一扫
微信扫一扫