一、什么是网络爬虫
随着大数据时代的来临,网络爬虫在互联网中的职位将越来越主要。互联网中的数据是海量的,若何自动高效地获取互联网中我们感兴趣的信息并为我们所用是一个主要的问题,而爬虫手艺就是为领会决这些问题而生的。
我们感兴趣的信息分为差别的类型:若是只是做搜索引擎,那么感兴趣的信息就是互联网中尽可能多的高质量网页;若是要获取某一垂直领域的数据或者有明确的检索需求,那么感兴趣的信息就是凭据我们的检索和需求所定位的这些信息,此时,需要过滤掉一些无用信息。前者我们称为通用网络爬虫,后者我们称为聚焦网络爬虫。


1. 初识网络爬虫
网络爬虫又称网络蜘蛛、网络蚂蚁、网络机器人等,可以自动化浏览网络中的信息,固然浏览信息的时刻需要根据我们制订的规则举行,这些规则我们称之为网络爬虫算法。使用Python可以很利便地编写出爬虫程序,举行互联网信息的自动化检索。
搜索引擎离不开爬虫,好比百度搜索引擎的爬虫叫作百度蜘蛛(Baiduspider)。百度蜘蛛天天会在海量的互联网信息中举行爬取,爬取优质信息并收录,当用户在百度搜索引擎上检索对应要害词时,百度将对要害词举行剖析处置,从收录的网页中找出相关网页,根据一定的排名规则举行排序并将效果展现给用户。
在这个历程中,百度蜘蛛起到了至关主要的作用。那么,若何笼罩互联网中更多的优质网页?又若何筛选这些重复的页面?这些都是由百度蜘蛛爬虫的算法决议的。接纳差别的算法,爬虫的运行效率会差别,爬取效果也会有所差异。
以是,我们在研究爬虫的时刻,不仅要领会爬虫若何实现,还需要知道一些常见爬虫的算法,若是有需要,我们还需要自己去制订响应的算法,在此,我们仅需要对爬虫的观点有一个基本的领会。
除了百度搜索引擎离不开爬虫以外,其他搜索引擎也离不开爬虫,它们也拥有自己的爬虫。好比360的爬虫叫360Spider,搜狗的爬虫叫Sogouspider,必应的爬虫叫Bingbot。
若是想自己实现一款小型的搜索引擎,我们也可以编写出自己的爬虫去实现,固然,虽然可能在性能或者算法上比不上主流的搜索引擎,然则个性化的水平会异常高,而且也有利于我们更深条理地明白搜索引擎内部的事情原理。
大数据时代也离不开爬虫,好比在举行大数据剖析或数据挖掘时,我们可以去一些对照大型的官方站点下载数据源。但这些数据源对照有限,那么若何才气获取更多更高质量的数据源呢?此时,我们可以编写自己的爬虫程序,从互联网中举行数据信息的获取。以是在未来,爬虫的职位会越来越主要。
2. 为什么要学网络爬虫
我们开端认识了网络爬虫,然则为什么要学习网络爬虫呢?要知道,只有清晰地知道我们的学习目的,才气够更好地学习这一项知识,我们将会为人人剖析一下学习网络爬虫的缘故原由。
固然,差别的人学习爬虫,可能目的有所差别,在此,我们总结了4种常见的学习爬虫的缘故原由。
1)学习爬虫,可以私人订制一个搜索引擎,而且可以对搜索引擎的数据采集事情原理举行更深条理地明白。
有的同伙希望能够深条理地领会搜索引擎的爬虫事情原理,或者希望自己能够开发出一款私人搜索引擎,那么此时,学习爬虫是异常有需要的。
简朴来说,我们学会了爬虫编写之后,就可以行使爬虫自动地采集互联网中的信息,采集回来后举行响应的存储或处置,在需要检索某些信息的时刻,只需在采集回来的信息中举行检索,即实现了私人的搜索引擎。
固然,信息怎么爬取、怎么存储、怎么举行分词、怎么举行相关性盘算等,都是需要我们举行设计的,爬虫手艺主要解决信息爬取的问题。

2)大数据时代,要举行数据剖析,首先要有数据源,而学习爬虫,可以让我们获取更多的数据源,而且这些数据源可以按我们的目的举行采集,去掉许多无关数据。
在举行大数据剖析或者举行数据挖掘的时刻,数据源可以从某些提供数据统计的网站获得, 也可以从某些文献或内部资料中获得,然则这些获得数据的方式,有时很难知足我们对数据的需求,而手动从互联网中去寻找这些数据,则花费的精神过大。
此时就可以行使爬虫手艺,自动地从互联网中获取我们感兴趣的数据内容,并将这些数据内容爬取回来,作为我们的数据源,从而举行更深条理的数据剖析,并获得更多有价值的信息。
3)对于许多SEO从业者来说,学习爬虫,可以更深条理地明白搜索引擎爬虫的事情原理,从而可以更好地举行搜索引擎优化。
既然是搜索引擎优化,那么就必须要对搜索引擎的事情原理异常清晰,同时也需要掌握搜索引擎爬虫的事情原理,这样在举行搜索引擎优化时,才气知己知彼,百战不殆。
4)从就业的角度来说,爬虫工程师现在来说属于紧缺人才,而且薪资待遇普遍较高,以是,深条理地掌握这门手艺,对于就业来说,是异常有利的。
有些同伙学习爬虫可能为了就业或者跳槽。从这个角度来说,爬虫工程师偏向是不错的选择之一,由于现在爬虫工程师的需求越来越大,而能够胜任这方面岗位的职员较少,以是属于一个对照紧缺的职业偏向,而且随着大数据时代的来临,爬虫手艺的应用将越来越普遍,在��来会拥有很好的生长空间。
除了以上为人人总结的4种常见的学习爬虫的缘故原由外,可能你另有一些其他学习爬虫的缘故原由,总之,不管是什么缘故原由,理清自己学习的目的,就可以更好地去研究一门知识手艺,并坚持下来。
3. 网络爬虫的组成

接下来,我们将先容网络爬虫的组成。网络爬虫由控制节点、爬虫节点、资源库组成。
上图所示是网络爬虫的控制节点和爬虫节点的结构关系。
可以看到,网络爬虫中可以有多个控制节点,每个控制节点下可以有多个爬虫节点,控制节点之间可以相互通讯,同时,控制节点和其下的各爬虫节点之间也可以举行相互通讯,属于同一个控制节点下的各爬虫节点间,亦可以相互通讯。
控制节点,也叫作爬虫的中央控制器,主要卖力凭据URL地址分配线程,并挪用爬虫节点举行详细的爬行。
爬虫节点会根据相关的算法,对网页举行详细的爬行,主要包罗下载网页以及对网页的文本举行处置,爬行后,会将对应的爬行效果存储到对应的资源库中。
4. 网络爬虫的类型
现在我们已经基本领会了网络爬虫的组成,那么网络爬虫详细有哪些类型呢?
网络爬虫根据实现的手艺和结构可以分为通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫等类型。在现实的网络爬虫中,通常是这几类爬虫的组合体。
4.1 通用网络爬虫
首先我们为人人先容通用网络爬虫(General Purpose Web Crawler)。通用网络爬虫又叫作全网爬虫,顾名思义,通用网络爬虫爬取的目的资源在全互联网中。
通用网络爬虫所爬取的目的数据是伟大的,而且爬行的局限也是异常大的,正是由于其爬取的数据是海量数据,故而对于这类爬虫来说,其爬取的性能要求是异常高的。这种网络爬虫主要应用于大型搜索引擎中,有异常高的应用价值。
通用网络爬虫主要由初始URL聚集、URL行列、页面爬行模块、页面剖析模块、页面数据库、链接过滤模块等组成。通用网络爬虫在爬行的时刻会接纳一定的爬行计谋,主要有深度优先爬行计谋和广度优先爬行计谋。
4.2 聚焦网络爬虫
聚焦网络爬虫(Focused Crawler)也叫主题网络爬虫,顾名思义,聚焦网络爬虫是根据预先界说好的主题有选择地举行网页爬取的一种爬虫,聚焦网络爬虫不像通用网络爬虫一样将目的资源定位在全互联网中,而是将爬取的目的网页定位在与主题相关的页面中,此时,可以大大节约爬虫爬取时所需的带宽资源和服务器资源。
聚焦网络爬虫主要应用在对特定信息的爬取中,主要为某一类特定的人群提供服务。
聚焦网络爬虫主要由初始URL聚集、URL行列、页面爬行模块、页面剖析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等组成。内容评价模块可以评价内容的主要性,同理,链接评价模块也可以评价出链接的主要性,然后凭据链接和内容的主要性,可以确定哪些页面优先接见。
聚焦网络爬虫的爬行计谋主要有4种,即基于内容评价的爬行计谋、基于链接评价的爬行计谋、基于增强学习的爬行计谋和基于语境图的爬行计谋。关于聚焦网络爬虫详细的爬行计谋,我们将在下文中举行详细剖析。
4.3 增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler),所谓增量式,对应着增量式更新。
增量式更新指的是在更新的时刻只更新改变的地方,而未改变的地方则不更新,以是增量式网络爬虫,在爬取网页的时刻,只爬取内容发生转变的网页或者新发生的网页,对于未发生内容转变的网页,则不会爬取。
增量式网络爬虫在一定水平上能够保证所爬取的页面,尽可能是新页面。
4.4 深层网络爬虫
深层网络爬虫(Deep Web Crawler),可以爬取互联网中的深层页面,在此我们首先需要领会深层页面的观点。
在互联网中,网页按存在方式分类,可以分为表层页面和深层页面。所谓的表层页面,指的是不需要提交表单,使用静态的链接就能够到达的静态页面;而深层页面则隐藏在表单后面,不能通过静态链接直接获取,是需要提交一定的要害词之后才气够获取获得的页面。
在互联网中,深层页面的数目往往比表层页面的数目要多许多,故而,我们需要想办法爬取深层页面。
爬取深层页面,需要想办法自动填写好对应表单,以是,深层网络爬虫最主要的部门即为表单填写部门。
深层网络爬虫主要由URL列表、LVS列表(LVS指的是标签/数值聚集,即填充表单的数据源)、爬行控制器、解析器、LVS控制器、表单剖析器、表单处置器、响应剖析器等部门组成。
深层网络爬虫表单的填写有两种类型:
第一种是基于领域知识的表单填写,简朴来说就是确立一个填写表单的要害词库,在需要填写的时刻,凭据语义剖析选择对应的要害词举行填写;
微信小程序如何发布,小程序发布流程及所需时间
第二种是基于网页结构剖析的表单填写,简朴来说,这种填写方式一样平常是领域知识有限的情况下使用,这种方式会凭据网页结构举行剖析,并自动地举行表单填写。
以上,为人人先容了网络爬虫中常见的几种类型,希望读者能够对网络爬虫的分类有一个基本的领会。
5. 爬虫扩展——聚焦爬虫
由于聚焦爬虫可以按对应的主题有目的地举行爬取,而且可以节约大量的服务器资源和带宽资源,具有很强的实用性,以是在此,我们将对聚焦爬虫举行详细解说。图1-2所示为聚焦爬虫运行的流程,熟悉该流程后,我们可以更清晰地知道聚焦爬虫的事情原理和历程。
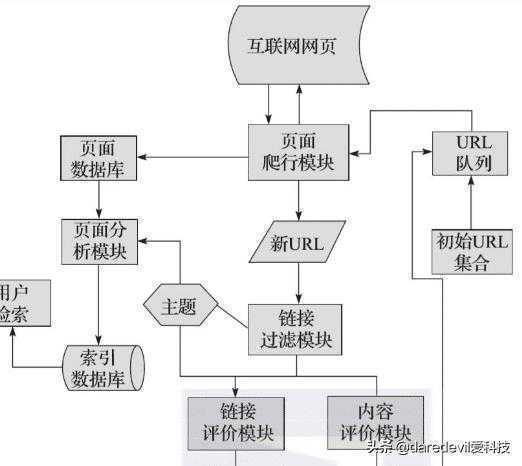
图1-2 聚焦爬虫运行的流程
首先,聚焦爬虫拥有一个控制中心,该控制中心卖力对整个爬虫系统举行治理和监控,主要包罗控制用户交互、初始化爬行器、确定主题、协调各模块之间的事情、控制爬行历程等方面。
然后,将初始的URL聚集通报给URL行列,页面爬行模块会从URL行列中读取第一批URL列表,然后凭据这些URL地址从互联网中举行响应的页面爬取。
爬取后,将爬取到的内容传到页面数据库中存储,同时,在爬行历程中,会爬取到一些新的URL,此时,需要凭据我们所定的主题使用链接过滤模块过滤掉无关链接,再将剩下来的URL链接凭据主题使用链接评价模块或内容评价模块举行优先级的排序。完成后,将新的URL地址通报到URL行列中,供页面爬行模块使用。
另一方面,将页面爬取并存放到页面数据库后,需要凭据主题使用页面剖析模块对爬取到的页面举行页面剖析处置,并凭据处置效果确立索引数据库,用户检索对应信息时,可以从索引数据库中举行响应的检索,并获得对应的效果。
这就是聚焦爬虫的主要事情流程,领会聚焦爬虫的主要事情流程有助于我们编写聚焦爬虫,使编写的思绪加倍清晰。
二、网络爬虫技术总览
在上文中,我们已经开端认识了网络爬虫,那么网络爬虫详细能做些什么呢?用网络爬虫又能做哪些有趣的事呢?在本章中我们将为人人详细解说。
1. 网络爬虫技术总览图
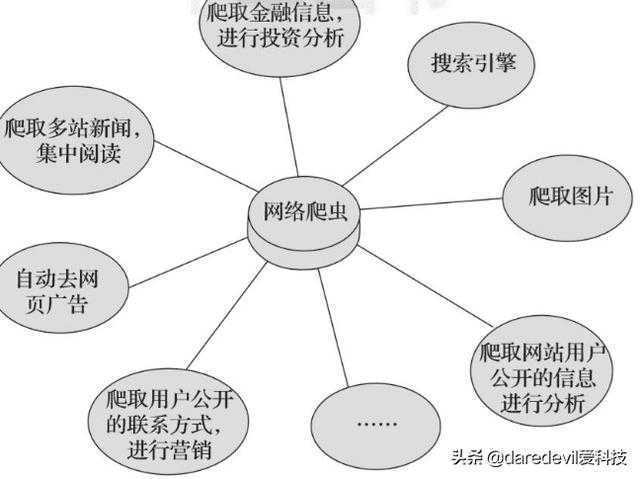
我们总结了网络爬虫的常用功效。
网络爬虫技术示意图
在图中可以看到,网络爬虫可以取代手工做许多事情,好比可以用于做搜索引擎,也可以爬取网站上面的图片,好比有些同伙将某些网站上的图片所有爬取下来,集中举行浏览,同时,网络爬虫也可以用于金融投资领域,好比可以自动爬取一些金融信息,并举行投资剖析等。
有时,我们对照喜欢的新闻网站可能有几个,每次都要划分打开这些新闻网站举行浏览,对照贫苦。此时可以行使网络爬虫,将这多个新闻网站中的新闻信息爬取下来,集中举行阅读。
有时,我们在浏览网页上的信息的时刻,会发现有许多广告。此时同样可以行使爬虫将对应网页上的信息爬取过来,这样就可以自动的过滤掉这些广告,利便对信息的阅读与使用。
有时,我们需要举行营销,那么若何找到目的客户以及目的客户的联系方式是一个要害问题。我们可以手动地在互联网中寻找,然则这样的效率会很低。此时,我们行使爬虫,可以设置对应的规则,自动地从互联网中采集目的用户的联系方式等数据,供我们举行营销使用。
有时,我们想对某个网站的用户信息举行剖析,好比剖析该网站的用户活跃度、谈话数、热门文章等信息,若是我们不是网站治理员,手工统计将是一个异常重大的工程。此时,可以行使爬虫轻松将这些数据采集到,以便举行进一步剖析,而这一切爬取的操作,都是自动举行的,我们只需要编写好对应的爬虫,并设计好对应的规则即可。
除此之外,爬虫还可以实现许多壮大的功效。总之,爬虫的泛起,可以在一定水平上取代手工接见网页,从而,原先我们需要人工去接见互联网信息的操作,现在都可以用爬虫自动化实现,这样可以更高效率地行使好互联网中的有用信息。
2. 搜索引擎焦点
爬虫与搜索引擎的关系是密不可分的,既然提到了网络爬虫,就免不了提到搜索引擎,在此,我们将对搜索引擎的焦点手艺举行一个简朴的解说。
图2-2所示为搜索引擎的焦点事情流程。首先,搜索引擎会行使爬虫模块去爬取互联网中的网页,然后将爬取到的网页存储在原始数据库中。爬虫模块主要包罗控制器和爬行器,控制器主要举行爬行的控制,爬行器则卖力详细的爬行义务。
然后,会对原始数据库中的数据举行索引,并存储到索引数据库中。
当用户检索信息的时刻,会通过用户交互接口输入对应的信息,用户交互接口相当于搜索引擎的输入框,输入完成之后,由检索器举行分词等操作,检索器会从索引数据库中获取数据举行响应的检索处置。
用户输入对应信息的同时,会将用户的行为存储到用户日志数据库中,好比用户的IP地址、用户所输入的要害词等等。随后,用户日志数据库中的数据会交由日志剖析器举行处置。日志剖析器会凭据大量的用户数据去调整原始数据库和索引数据库,改变排名效果或举行其他操作。
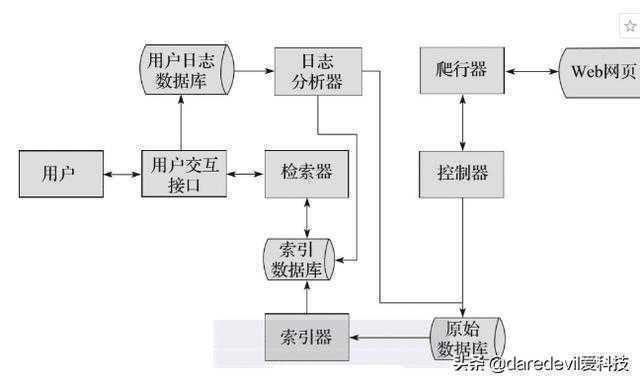
图2-2 搜索引擎的焦点事情流程
以上就是搜索引擎焦点事情流程的简要概述,可能人人对索引和检索的观点还不太能区分,在此我为人人详细讲一下。
简朴来说,检索是一种行为,而索引是一种属性。好比一家超市,内里有大量的商品,为了能够快速地找到这些商品,我们会将这些商品举行分组,好比有一样平常用品类商品、饮料类商品、服装类商品等组别,此时,这些商品的组名我们称之为索引,索引由索引器控制。
若是,有一个用户想要找到某一个商品,那么需要在超市的大量商品中寻找,这个历程,我们称之为检索。若是有一个好的索引,则可以提高检索的效率;若没有索引,则检索的效率会很低。
好比,一个超市内里的商品若是没有举行分类,那么用户要在海量的商品中寻找某一种商品,则会对照艰苦。
3. 用户爬虫的那些事儿
用户爬虫是网络爬虫中的一种类型。所谓用户爬虫,指的是专门用来爬取互联网中用户数据的一种爬虫。由于互联网中的用户数据信息,相对来说是对照敏感的数据信息,以是,用户爬虫的行使价值也相对较高。
行使用户爬虫可以做大量的事情,接下来我们一起来看一下行使用户爬虫所做的一些有趣的事情吧。
2015年,有知乎网友对知乎的用户数据举行了爬取,然后举行对应的数据剖析,便获得了知乎上大量的潜在数据,好比:
知乎上注册用户的男女比例:男生占例多于60%。
知乎上注册用户的区域:北京的人口占有比重最大,多于30%。
知乎上注册用户从事的行业:从事互联网行业的用户占有比重最大,同样多于30%。
除此之外,只要我们仔细挖掘,还可以挖掘出更多的潜在数据,而要剖析这些数据,则必须要获取到这些用户数据,此时,我们可以使用网络爬虫手艺轻松爬取到这些有用的用户信息。
同样,在2015年,有网友爬取了3000万QQ空间的用户信息,并同样从中获得了大量潜在数据,好比:
QQ空间用户发说说的时间纪律:晚上22点左右,平均发说说的数目是一天中最多的时刻。
QQ空间用户的出生月份漫衍:1月份和10月份出生的用户较多。
QQ空间用户的年龄阶段漫衍:出生于1990年到1995年的用户相对来说较多。
QQ空间用户的性别漫衍:男生占比多于50%,女生占比多于30%,未填性别的占10%左右。
除了以上两个例子之外,用户爬虫还可以做许多事情,好比爬取淘宝的用户信息,可以剖析淘宝用户喜欢什么商品,从而更有利于我们对商品的定位等。
由此可见,行使用户爬虫可以获得许多有趣的潜在信息,那么这些爬虫难吗?实在不难,相信你也能写出这样的爬虫。

三、小结
网络爬虫也叫作网络蜘蛛、网络蚂蚁、网络机器人等,可以自动地浏览网络中的信息,固然浏览信息的时刻需要根据我们制订的规则去浏览,这些规则我们将其称为网络爬虫算法。使用Python可以很利便地编写出爬虫程序,举行互联网信息的自动化检索。
学习爬虫,可以:①私人订制一个搜索引擎,而且可以对搜索引擎的数据采集事情原理,举行更深条理地明白;②为大数据剖析提供更多高质量的数据源;③更好地研究搜索引擎优化;④解决就业或跳槽的问题。
网络爬虫由控制节点、爬虫节点、资源库组成。
网络爬虫根据实现的手艺和结构可以分为通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫等类型。在现实的网络爬虫中,通常是这几类爬虫的组合体。
聚焦网络爬虫主要由初始URL聚集、URL行列、页面爬行模块、页面剖析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等组成。
爬虫的泛起,可以在一定水平上取代手工接见网页,以是,原先我们需要人工去接见互联网信息的操作,现在都可以用爬虫自动化实现,这样可以更高效率地行使好互联网中的有用信息。
检索是一种行为,而索引是一种属性。若是有一个好的索引,则可以提高检索的效率,若没有索引,则检索的效率会很低。
用户爬虫是网络爬虫的其中一种类型。所谓用户爬虫,即专门用来爬取互联网中用户数据的一种爬虫。由于互联网中的用户数据信息,相对来说是对照敏感的数据信息,以是,用户爬虫的行使价值也相对较高。
本文来源于自互联网,不代表n5网立场,侵删。发布者:虚拟资源中心,转载请注明出处:https://www.n5w.com/48414.html
 微信扫一扫
微信扫一扫